

この記事は代表の藤井迪生が一般社団法人日本船長協会の月報 Captain 第 477 号 (2023年12月)に投稿したものを再編集の上、再掲しています。
ChatGPTに利用されているモデルであるGPT(Generative Pre-trained Transformer)は言語モデルと呼ばれる、「ある単語が出現した後にどの単語がくる確率が高いかを膨大な学習データをもとに算出する[1]」計算モデルで構築されています。
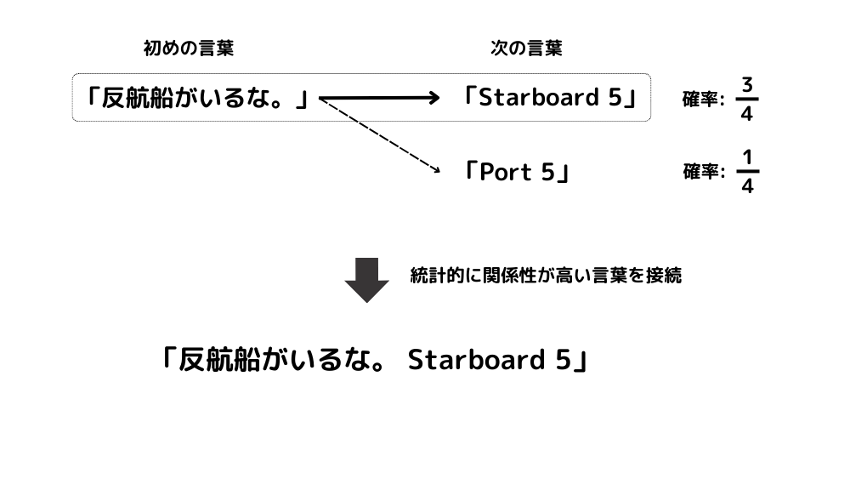
例えば、当直航海士が「反航船がいるな。」と発言した後に来る言葉の確率が「Starboard 5」が3/4、「Port 5」が1/4だったとすると、「反航船がいるな。Starboard 5」というように、次に来る確率の高い言葉を探し出し、それらを組み合わせて結果を出力します。(図1)
シンプルに書きましたが、実際には大量のデータを使って1,000億を超えるパラメータで文章の特徴とその関係性を統計的に計算し出力しています。人間が一生に知り得る情報よりも遥かに多くのデータとパターンを読み込んで作成した大規模言語モデルは、今日、人間の想像を遥かに超える言語処理能力を有しており、この技術進歩のスピードでいけば、これまで「仕事が早い」、「優等生」と言われていた人間が、より大量の「知識」や「常識」を学習したAIにより代替される時代が、すぐそこまで来ているように感じます。
話が少し逸れますが、今日のAIの飛躍的な発展に貢献したのは2017年にGoogleの研究者のAshish Vaswani氏らが論文「Attention Is All You Need」[2]で発表したTransformerという手法だと言われています。Ashish氏らは全ての言葉を処理するのではなく、重要な意味を持つ言葉のみに着目して関係性を計算すると従来のAIよりも精度と処理速度が上がることに気づき、発表しました。これによりコンピュータが従来よりも膨大なデータ量を短時間で学習できるようになり、文章の意味や特徴を掴む性能が格段に向上しています。
[1] Samuel R. Bowman, Eight Things to Know about Large Language Models, arXiv:2304.00612, URL: https://doi.org/10.48550/arXiv.2304.00612, 2 Apr 2023
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, Attention Is All You Need, arXiv:1706.03762, URL: https://doi.org/10.48550/arXiv.1706.03762, 12 Jun 2017

