

この記事は代表の藤井迪生が一般社団法人日本船長協会の月報 Captain 第 477 号 (2023年12月)に投稿したものを再編集の上、再掲しています。
ここで大規模言語モデルをはじめとする生成AIがどのように作られ、どのように利用されているかについて、少し触れてみたいと思います。 生成AIを利用するには、「学習」と「推論」の2つのプロセスが必要となります。学習とは、生成AIモデルに大量のデータを入力してパラメータを最適化するプロセスを意味し、与えられたデータから関係性やパターンを学習して、それらを予測するモデルを作成します。 一方、推論は、学習が終わったモデルを利用して、ユーザーの入力に対する回答として相応しい文章を予測して生成するプロセスです。「対話型AI(例えばChatGPTなど)を利用する」とは一般的にはこの推論のプロセスのみを指すことが多く、学習済みのモデルを使ってユーザーが入力した言葉に対する統計的に近しい言葉を推論の上、その結果をユーザーに返す動作を行っています。(図2)
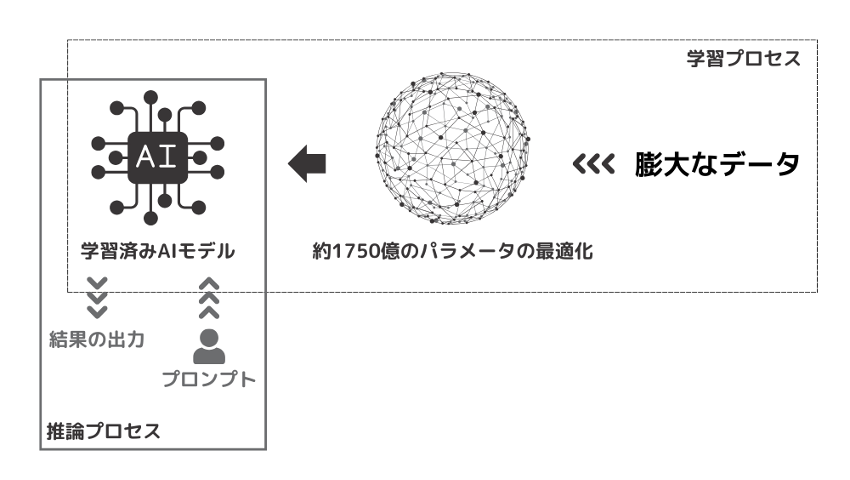
生成AIに対してユーザーが入力する命令文章は「プロンプト」と呼ばれ、プロンプトの書き方によって推論結果が異なることから、最近はその効果的な書き方についてビジネス系雑誌等でも特集されているのを見かけます。 ところで、前述の「学習」、「推論」の両プロセスでは膨大な計算が必要なため、普通のPCよりも遥かに高性能な計算機が必要です。そのため、ChatGPTを利用する場合は、①ユーザーの端末でプロンプトを入力し、②入力したプロンプトがインターネットを経由してOpenAI社のサーバーに送信され、③サーバー上で推論を実行後、④インターネットを経由して結果がユーザーの端末に送られる、という流れで処理されます。

