

この記事は代表の藤井迪生が一般社団法人日本船長協会の月報 Captain 第 478 号 (2024年2月)に投稿したものを再編集の上、再掲しています。
検索と聞いてまずイメージするのはキーワード検索です。例えば、「海上衝突予防法(スペース)横切り船」といったように、調べたい質問に含まれるいくつかのキーワードを使ってインターネット上にあるデータから関連する情報を探し出す方法です。この方法を利用する場合、 (1) 検索キーワードでデータを検索し、(2) 検索結果から質問の意図と近いデータを選び、(3) プロンプトにそのデータと質問を入力して、(4) 結果を出力させるというプロセスを踏む必要があります。しかし、(1)でユーザーは質問文から検索に必要なキーワードを定義する必要があり、また、キーワード検索の場合はデータベースに保存するデータはキーワードで検索ができるように整理されている必要があります。
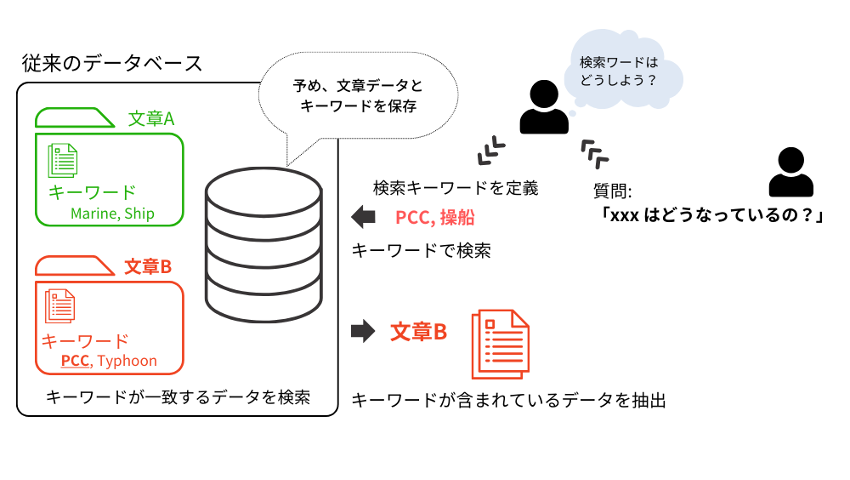
さらに、同じ意味でも違う単語でキーワード登録されている場合、例えば、「横切り船」と「Crossing Vessels」は同じ意味ですが、「横切り船」でキーワード検索した場合には「Crossing Vessels」のデータは抜き出せません。
これらの課題を解決するのが、最近注目されているEmbeddings(エンべディックス)を使ったベクトル検索[1]です。
Embeddingsは膨大なデータを学習した機械学習モデル(いわゆるAI)を利用して、文章の意味をベクトルデータに変換する技術です。ベクトル(数値)で処理されるため、異なる言語や細かな表記揺れがあった場合でも同じ意味であれば同じ方向性のベクトルが得られるように設計されており、文章の意味に沿った類似性を判定することが可能になっています。
例えば、今、(a)「船長が操船をしている」、(b)「航海士が航海当直をしている」、(c)「The master manoeuvring a ship.」、(d)「自動車整備士がエンジンオイルを交換している」という4つの文があり、これをEmbeddingsモデルでベクトルに変換した値が、それぞれa:(0.025, 0.025)、b:(0.0796, 0.0796)、c:(0.0531,0.1603)、d:(−0.1330,−0.0662)とします。これらのベクトルをプロットしてみると、以下の図のようになり、(a) に対して(b)と(c)の意味のベクトルが近く、(d) は遠いというように、意味の類似性をベクトルの位置関係で求めることが可能となります。
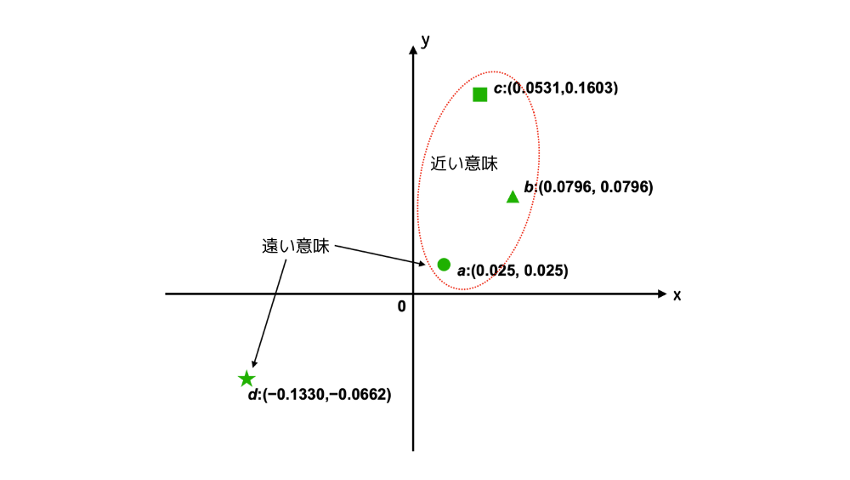
例では2次元のベクトルで表現しましたが、実際には高次元、例えばOpenAIのEmbeddingsモデルであるtext-embedding-ada-002の場合には1536次元の空間ベクトルにプロットするため、人間が視覚的に判別することは不可能ですが、計算機であるコンピュータが高次元のベクトルの角度(または距離)を計算して、一番角度が小さいもの(または距離が近いもの)から順に類似性が高いものと判定して結果を表示することが可能です。つまり、データベースに収められている文章をEmbeddingsに変換し、そのベクトルを検索することで、類似する意味を持つ文章を検索することができるようになるのです。
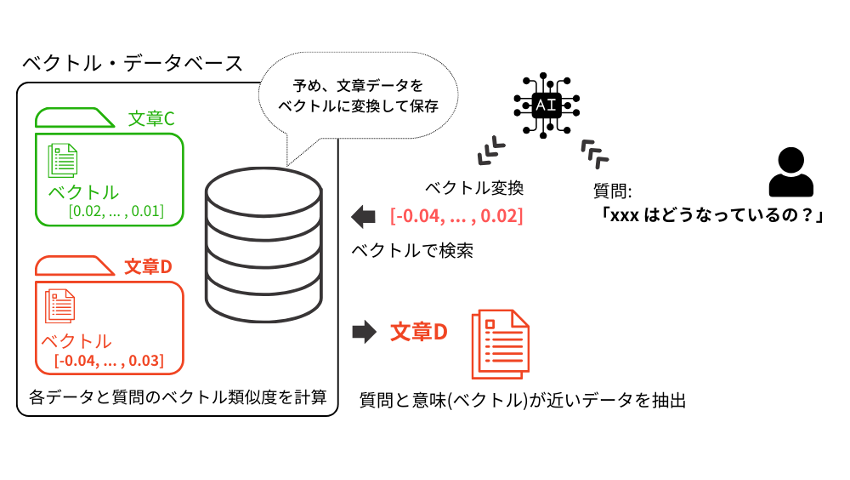
このベクトル検索とGPTを組み合わせることで、プロンプトに質問内容を入力するだけで、自動で必要な専門知識をLLMに与えて推論させることが可能になるのです。
[1] Kaz Sato, Tomoyuki Chikanag, あらゆるデータの瞬時アクセスを実現する Google のベクトル検索技術, URL: https://cloud.google.com/blog/ja/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology, 16 Dec. 2021

